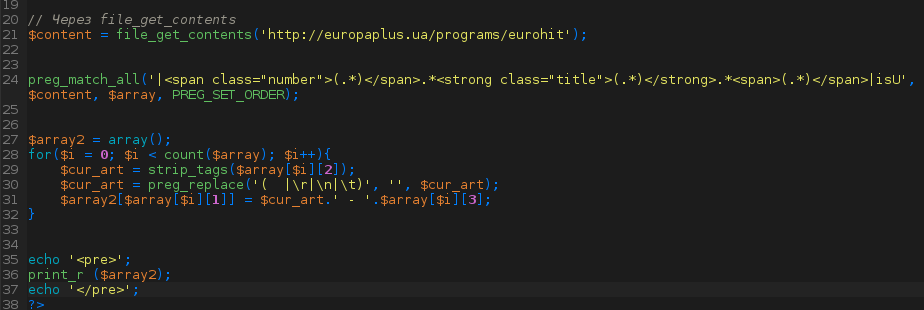
Добрый день всем.
Понадобилось мне вообщем создать робота на своем сайте, который из заполненных инпутов создавал http запрос (невидимо для пользователя) брал оттуда (с другого сайта по этому запросу) цену, возвращался на мой сайт и вставлял ее там.
Я понимаю, что такие вещи должны существовать - иначе зачем было бы изобретать каптчу - но даже не представляю как запрос в гугл забить!
Ничего криминального делать не собираюсь) просто раньше без этого обходились, а теперь необходимо постоянно ориентироваться от цены монополиста.
Поможете?
Понадобилось мне вообщем создать робота на своем сайте, который из заполненных инпутов создавал http запрос (невидимо для пользователя) брал оттуда (с другого сайта по этому запросу) цену, возвращался на мой сайт и вставлял ее там.
Я понимаю, что такие вещи должны существовать - иначе зачем было бы изобретать каптчу - но даже не представляю как запрос в гугл забить!
Ничего криминального делать не собираюсь) просто раньше без этого обходились, а теперь необходимо постоянно ориентироваться от цены монополиста.
Поможете?